Impression of Big Data 12 Oct 2016
随着目前数据量的发展, 传统的数据处理模式越来越难以满足要求. 下面通过Big Data一书介绍的大数据处理模式来看一下该书中的大数据处理架构如何进行数据处理以及规避传统数据库处理数据时的一些弊端.
下面使用书中给出的示例进行介绍, 假设有一个类似于Google Analytics的功能, 能够统计用户对页面浏览情况, 该应用能够统计互联网上的任意页面的访问量, 另外该应用也能统计访问量前100的URLs
传统数据库处理数据方式以及缺点
为了解决上面的问题, 我们建立一个传统数据库的数据模型, 如下表
| 列 名 | 类 型 |
|---|---|
| id | integer |
| user_id | integer |
| url | varchar(255) |
| pageviews | bigint |
当用户点击访问了一个URL, 该用户所对应的url的记录的pageviews值增1, 该设计在低访问量的情况下可以完美的执行. 但是一旦访问量变高, 由于需要频繁从数据库读取记录并更新, 会造成更新数据超时. 如果我们希望快速修正这个问题, 那么在访问数据层之前添加一个缓存队列是一个不错的选择. 当统计应用收到一个页面访问请求, 该事件会直接进入队列, 另外一个线程每次读取100个页面访问请求, 并进行聚合后更新到数据库中, 这种方案可以很好的解决数据库数据更新超时的问题, 而且还有一个好处, 如果后续访问量再次增大, 我们只需要将队列大小调大即可.
但是当该应用变的越来越受欢迎, 数据库最终会再一次成为瓶颈, 通过Google查询”how to scale a write-heavy relational database”, 你获得最佳的答案可能是使用多个数据库服务器, 使每一个数据库服务器保存一部分数据, 这就是人们常说的数据水平切分或者数据分片. 该解决方案是将数据库的写负载分摊到多个机器上. 而我们选择对数据的键值做hash, 并对其使用数据分片个数取模.
加入数据分片后, 所有的应用程序代码需要知道数据分片的存在, 例如上面提到的统计访问量前100的URLs的功能, 我们需要使应用程序对每个分片计算访问量前100的URLs, 并最终汇总到一个服务器上然后进行合并, 得到最终访问量最高的100个URLs. 而且等到这个应用程序越来越欢迎, 为了能够添加更多的数据分片, 我们需要对其重新分片. 而这个过程也会变得越来越痛苦, 因为应用程序里各个功能都需要对分片的加入做相应的协调. 一旦某一个地方忘记更新最新的分片数, 就可能会导致新数据被放到错误的分片上, 而这种错误基本上只能依靠脚本来将所有的数据重新再做一次分片来解决, 这个时间实在是无法估量.
随之而来的问题
- 随之分片越来越多, 数据库集群部分机器down掉的几率就大了很多, 这些down掉的机器上的数据就变得不可用, 你可能需要如下方法来解决这个问题 ** 更新队列缓存程序, 额外添加一个”Pending”队列, 所有因为机器响应或者其他问题导致的写入超时的数据均添加到这个队列, 然后每隔几分钟, 将该队列的数据写入的数据库中 ** 利用数据库副本的功能, 为每一个分片数据库创建副本, 当master down掉后, 虽然此时无法写入数据, 但是仍然可以保证用户能够读取之前的数据.
- 一旦程序有bug, 比如正确的情况下一次访问记录一个点击量, 而程序错误造成一次访问记录了两个点击量, 而这个错误上线后, 我们1天后才发现, 及时有备份, 我们也没办法将数据修正, 因为我们不知道哪些数据遭到了破坏.(这些数据基本上已经没有用了, 因为你只有一周前这个URL的点击量, 而这些URLs后续实际被点击了多少次也无从得知)
为什么大数据能够解决上面的问题?
- 首先, 大数据技术相关的数据存储方案都提供了分布式特性, 也就是说数据分片, 数据副本等这些逻辑都内置于数据库中, 我们不再需要对其进行关心, 不会再出现查错分片的情况, 当我们需要对程序作出扩展时, 只需要添加节点, 系统会自动将数据re-banlance到新节点.
- 另外, 由于传统数据库数据量的限制, 我们设计模型时数据往往是可变的, 这样也就导致了我们很难恢复因为bug导致的数据错误或缺失. 而引入大数据的解决方案后, 数据量不再是瓶颈, 我们在设计数据模型时就可以将可变数据模型转化为不可变数据模型, 系统中的数据一旦被保存就不会被修改, 后续的改动都是通过新增数据来达成的, 即使程序问题导致有错误数据, 这部分错误数据也不会影响之前没有问题的数据.
理想中的大数据系统需要具备的特点
- 健壮性和容错性
- 低延时的读和写
- 伸缩性
- 通用性
- 可扩展性
- 最小的维护代价
- 容易排错
Lambda架构
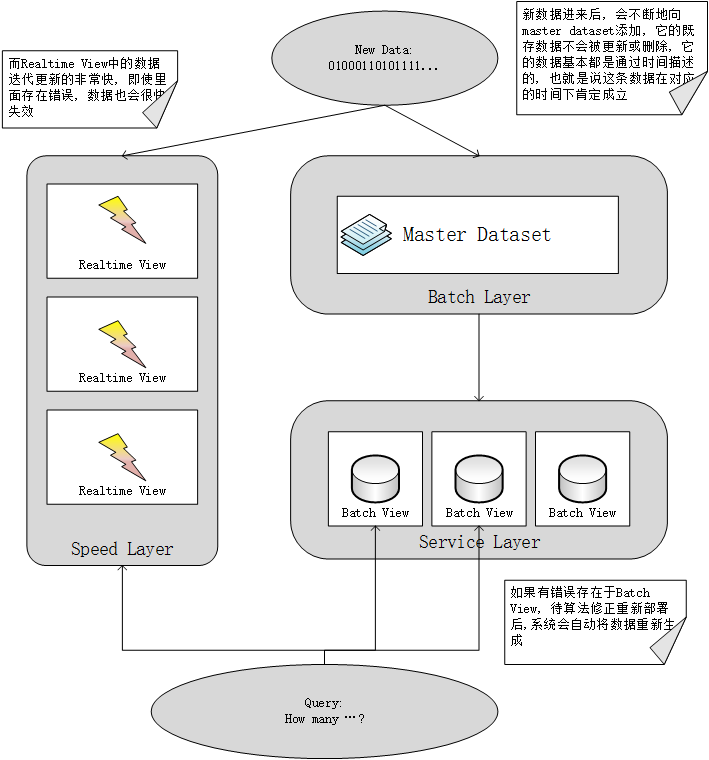
Lambda架构如何满足以上特点
| 特 点 | 描 述 |
|---|---|
| 健壮性和容错性 | 当机器down掉后, Hadoop帮助我们进行故障转移, Service Layer使用数据副本来保证在部分机器down掉时数据的可用性; 另外Batch Layer和Service Layer也解决了容错性的问题, 即使我们计算过程中存在bug, 当我们修复这些bug后, 在原始数据上再重新计算就可以得到正确的视图 |
| 低延时的读和写 | Speed Layer和Service Layer的结合为我们解决了低延时读的问题, 写操作只需要将原始数据写入存储即可 |
| 伸缩性 | Lambda三层架构设计中每一层都有完善的分布式实现方案, 我们只需要根据实际需求增减机器即可 |
| 通用性 | lambda架构没有引入任何领域的概念, 它可以根据任意数据计算生成出任意的视图 |
| 可扩展性 | 添加一个新的视图只需要为其添加一个新的计算函数即可, 如果需要更新原来的视图, 只需要在原函数上进行修改, 不需要担心历史数据, 因为系统会根据新的算法重新计算视图 |
| 最小的维护代价 | 架构中最主要的需要维护的部分是hadoop集群, 但只要有一些hadoop运维知识的人即可, service layer基本上可以认为是一个数据库 |
| 容易排错 | 在Batch Layer中所有的数据不会被删除, 所以一旦有错误发生, 可以根据当时的数据快速定位错误. |
Batch Layer
Batch Layer主要负责数据集的存储以及预计算, 该数据集是Lambda架构的一切数据的来源, 即使丢失了Service Layer和Speed Layer上所有的数据, 你也可以通过该数据集重新构建整个应用, 因为Batch Views中的数据是由Batch Layer中的数据集计算而得的, Speed Layer中的数据是基于近期数据计算所得.
数据建模以及存储
当我们存储数据以及使用数据时, 第一件需要做的是就是定义我们要使用的数据, 以及这些数据如何存取
数据的定义
假设有一个类似于Facebook的社交网站, 需要提供以下信息:
- A的关注好友和取消关注的事件
- A当前的好友关注列表
- A当前关注的好友数
上面这个例子阐明了信息依赖的问题, 我们通过上面1的信息可以得到2和3信息, 通过2信息可以得到3, 但是反过来, 比如你只有A当前关注的好友数, 你无法获知A当前的好友关注列表
信息: 通过我们的数据系统可以获取的任何知识, 类似于我们平时说的数据的意思;数据: 表示那些无法再切分为其他数据的信息, 通过这些数据可以得到其他所有我们想要知道的信息;查询: 基于数据而产生的问题视图: 基于数据而生成的信息, 通过它来回答上面的问题
数据的特征
- Rawnest(原始数据): 任何经过加工的数据, 都有可能丢失其原来包含的信息
- Immutable(不变性): 通过使用不变的数据, 可以更好的避免错误产生的影响, 简化你的业务逻辑
- Perpetuity(永恒性): 如果要保证数据的不变性, 那么就需要要求数据永远都有效, 后面介绍的
基于事实的数据模型就是通过在数据上添加时间戳, 表明在这个时间点, 数据描述的内容是有效的.
基于事实的数据模型
下面举几个例子来说明这种模型:
比如A在2016年11月1日12点51分13秒的时候在某个网站更新了自己的住址为北京, 那么该数据可以表示为
{
"name" : "A",
"location": "beijing",
"timestamp": "2016-11-01 12:51:13"
}当A在2016年12月1日10点13分23秒的时候又更新为上海, 那么该数据表示为
{
"name" : "A",
"location": "shanghai",
"timestamp": "2016-12-01 10:13:23"
}这条数据直接被新增至数据库, 而并不会讲原来的数据覆盖, 即保证了数据的不可变性 从上面这两条数据我们可以认为在2016年11月1日12点51分13秒到2016年12月1日10点13分23秒期间A的住址一直是北京, 而从2016年12月1日10点13分23秒至今其住址为上海.
假设我们使用关系型数据库来保存A的住址, 当A更新了自己的住址后, 数据只保存更新后的地址, 那么我们只能从这些数据中获知A现在的住址, 而使用基于事实的数据模型, 我们可以通过这些数据获知我们想知道的一切历史信息以及当前信息
A在这个网站更新了自己的地址和年龄, 但是没有填写兴趣信息, 如果在传统数据库中用户信息表中兴趣字段就会为空, 而对于基于事实的数据模型, 由于数据是不可拆分的, 所以地址会保存一条数据, 年龄也会保存一条数据, 兴趣缺失则该数据不会进行保存, 避免了NULL数据
再设想我们的程序出错, 导致我们更新后的数据是错误的, 对于关系型数据库, 我们无法直接从数据上获知正确的地址是什么, 而使用基于事实的数据模型, 我们只需要简单的将错误数据删除, 重新计算后, 我们的查询结果(views)即可恢复
基于事实的数据模型的优势
- 任何时间点的信息都可以查询: 由于我们将所有事件添加了时间戳, 这样凭借大数据技术将大量的这种数据进行保存, 而不是像传统数据库一样只保存当前的数据, 这样使得我们不光能够查询当前的信息, 也能够查询以前任何时间段的历史信息.
- 更好的容错性: 基于事实的数据模型中的数据不会被修改和删除, 只会新增, 如果因为程序问题导致的错误数据进来, 那么我们只需要将错误数据删掉, 重新计算后即可恢复上一个正确状态
- 有助于对不完整的数据处理: 基于事实的数据模型中的数据是不可拆分的, 每一个单一的信息都会被分开保存, 它不会像传统数据库一样将一系列信息放到一张表中保存, 所以它只需要保存存在的数据, 不会像传统数据库一样产生NULL数据
- 经过处理的数据与原始数据分别保存: 原始数据保存在Batch Layer, 经过处理的数据存放在Service Layer和Speed Layer, 如果后续数据处理程序优化, 重新刷新Service Layer和Speed Layer即可将优化作用在所有的数据上.
Graph Schema
因为在基于事实的数据模型中每一个事实只记录单一的信息, 而我们大部分应用使用到的信息肯定拥有多种维度的信息, 它们之间再建立各种各样的关系
Graph Schema基于事实的数据模型构建, 即每一个单一的信息(事实)为图中的节点, 这些信息之间的联系为连接节点的线表示信息之间的关系
Graph Schema的构成
- 节点是数据系统中的实体, 如节点代表一个用户, 那么这个节点可能由用户ID来表示
- 连线代表实体之间的关系, 比如两个用户之间的连线代表两个用户之间好友关系, 连线只能连接两个节点
- 属性代表实体的信息, 如用户的住址, 年龄等
下图表示了Graph Schema的三个构成部分
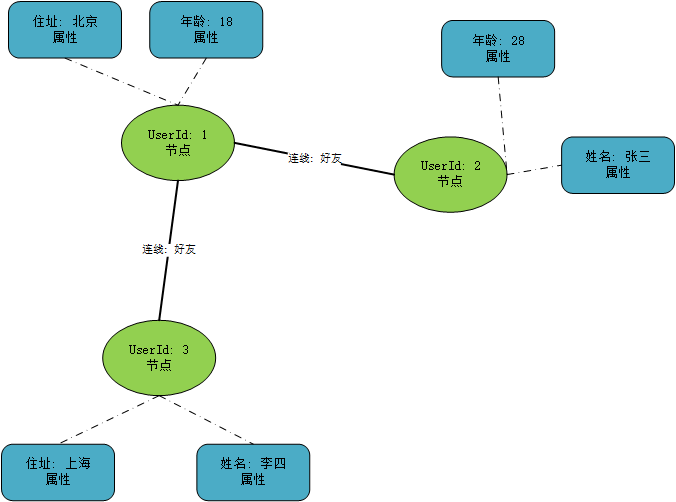
信息基于事实来保存, Graph Schema描述这些事实的类型, 为了保证所有必须字段都有值, 并且传入的数据是期望的类型, 所以选用严格的数据格式来对数据进行存储, 下面我们以Thrift实现的网页浏览统计所需要的数据模型
引入序列化框架的必要性
许多人喜欢使用类似json这种半结构化的数据格式, 理由是当后续业务发展, 可以快速增减字段. 但是像json这种灵活的数据结构容易导致由于程序问题导致错误数据进来后, 无法追踪以及排错. 而使用严格的数据格式在构建数据时, 对于一些非法数据就可以及时获得其错误原因, 另外通过类似strack trace等信息可以获知什么时候这条数据开始出错的(这是json无法达到的), 而且引入序列化框架额外的好处是能够自动为各个语言平台生成代码, 使其可以被不同语言平台使用.
网站数据统计分析中的数据模型 – Thrift实现
节点
对于这个应用来说, 主要涉及到两个实体: 用户和页面, 这里使用Thrift中的union来定义节点
union PersonID {
1: string cookie;
2: i64 user_id;
}
union PageID {
1: string url;
}连线
对于应用来说, 涉及到的关系有用户-用户的等价关系(两个用户实体其实指向的是同一个人, 比如新用户通过ip-a访问了网站, 在该网站上注册了一个用户user-a, 那个PersonID(ip-a)等价于PersonID(user-a)), 用户-页面的浏览关系
struct EquivEdge {
1: required PersonID id1;
2: required PersonID id2;
}
struct PageViewEdge {
1: required PersonID person;
2: required PageID page;
3: required i64 nonce;
}由于对于关系来说, 肯定是两个实体间的关联, 所以对于两个实体的字段是必填字段.
struct是Thrift中基本的组合类型, 每一个字段都需要通过required或optional进行修饰, 如果一个字段被required修饰, 该字段的值就必须被提供, 不然Thrift在序列化或反序列化时会报错
而union类似于C++中的union, 它的结构和struct类似, 但与struct显著的区别就是union中定义的诸多字段中同时只能有一个有效
属性
一个属性包含一个节点和一个属性值, 属性值可以是各种属性类型中的其中之一, 所以我们使用union定义
对于网页来说, 只有一个属性需要进行定义
union PagePropertyValue {
1: i32 page_views;
}
struct PageProperty {
1: required PageID id;
2: required PagePropertyValue property;
}用户相对来说复杂一些
struct Location {
1: optional string city;
2: optional string state;
3: optional string country;
}
enum GenderType {
MALE = 1,
FEMALE = 2
}
union PersonPropertyValue {
1: string full_name;
2: GenderType gender;
3: Location location;
}
struct PersonProperty {
1: required PersonID id;
2: required PersonPropertyValue property;
}将以上数据糅合在一起
union DataUnit {
1: PersonProperty person_property;
2: PageProperty page_property;
3: EquivEdge equiv;
4: PageViewEdge page_view;
}
在存储时每一个数据单元都可以选择属性中的一项
struct Pedigree {
1: required i32 true_as_of_secs;
}
每一个数据都需要添加时间戳
struct Data {
1: required Pedigree pedigree;
2: required DataUnit dataunit;
}数据存储
基于前面对数据的定义, 数据是不可变的并且永远有效, 数据存储主要的操作就是将新的数据拼接在原来的数据后, 在后续计算Batch Views时, 需要一次性读取大批量的数据, 并且由于我们要保存所有历史数据并且读取这些数据, 所以我们需要为这种大数据量的, 并且持续增长的数据操作进行优化; 另外, 随机读取其中部分数据并不需要
根据上述对数据存储方案的需求的描述, 分布式文件系统是最符合需求的方案
垂直切分
虽说Batch Layer的计算是基于整个数据集的, 但是大部分的计算并不需要扫描完整的数据集, 比如一些结算只需要扫描过期两个月的数据, 或者计算用户登录活动信息, 只需要扫描登录相关的数据, 垂直切分将数据按照类别, 时间进行切分, 这样我们在计算Batch Views时只需要扫描计算相关的数据.
Batch Layer上的计算
Service Layer
Speed Layer
Queue设计演变过程
在异步程序中, 当一个事件到来, 客户端将其分配到一个worker中执行, 缺点: 无法获知事件处理的结果, 出错无法重试; 一旦过量的事件进入系统, 可能会导致系统奔溃
Queue的引入
interface Queue {
void add(Object item);
Object poll();
Object peek();
}上面是java的Queue的接口, 而最简单的队列实现-单消费者队列架构基本和其类似, Kestrel和RabbitMQ使用了这种结构
class Item {
Long id;
byte[] item;
}
interface Queue {
void add(Item item);
Item get();
void ack(Long id);
void fail(Long id);
}使用上面的结构, 当事件被处理完, 使用ack通知队列该事件可以删除, 而调用fail时, 事件不会被删除, 而会被分配给其他worker.
但是这种结构有一个缺点就是一个事件只能被消费一次, 如果有多个功能需要消费这个事件的话, 最简单的方式就是将这些功能封装在一个应用, 但是这种做法违背了隔离性, 如果是一个公司的多个组来消费这个事件的话, 采用这种方式会造成极大的维护成本
为了解决这个问题, Broker(中介)被引入
在Speed Layer中, 根据不同的需求以及使用场景, 通常有两种数据处理方式, 一种是一次只处理一条数据, 当数据处理过程发生错误时, 重试也只是对这一条数据进行重试; 另外一种方式是一次处理一批数据, 在数据处理过程中, 也必须严格按照数据的顺序进行处理, 只有当本批次数据处理完成, 才能处理下批次数据
更深层度的挖掘Lambda架构
一些平时工作相关的感想
通过上述介绍的Lambda架构, 从中可以看到Batch Layer中的数据存储全部采用不可变的数据结构, 这样大大的减少了数据处理的复杂度, 因为只有新增和查询操作, 只要数据进入了系统, 该数据不会再进行改变
在我们的工作场景中, 有一个需求需要在某些条件达成下, 自动触发一个或多个命令, 这些需要达成的条件我们可以把它们作为事件, 存储到数据库中, 我们只会定期清理相对较老的同类事件, 这样保证了数据库数据量的规模不会太大. 同时又保证相关逻辑不会太复杂
另外在日常的编程习惯中, 尽可能地使用final字段, 它可以避免引用以及值被意外更改
像书中所总结的query=function(all data), 我们在构造一个方法时尽可能地少依赖上下文, 也就是说类和类, 方法和方法之间模块化, 它们完成功能不需要依赖任何其他的状态, 一个方法对应于一个特定的输入, 它的返回只应该是一个, 这样我们的程序才有可能可控, 风险更低. 工作中常遇到其他组的人遇到各种奇葩问题, 都是由于方法中依赖的一个状态意外被更改而导致的, 而这些错误有时引起的后果又是不可估量的.
References
Big Data